I've been avoiding to do a write-up on this section for several reasons.
First, I'm using the IDA disassembler which is pretty expensive and thus quite extensively pirated. Unfortunately there are no freely available tools that I know of that can perform this task.
Second, I really suck at assembler and C so might not be the best person to do these analysis. I've used the freely available Thumb decompiler plugin which is able to translate assembly into readable code but only in about 30% of the cases. There's no substitute for knowledge, it seems.
Part 1: http://hackcorrelation.blogspot.de/2013/07/txtr-beagle-teardown-part-1.html
Part 2: http://hackcorrelation.blogspot.de/2013/07/txtr-beagle-part-two-software.html
Part 3: http://hackcorrelation.blogspot.de/2013/07/txtr-beagle-part-3-storage-and-transfer.html
Part 4: http://hackcorellation.blogspot.de/2013/07/txtr-beagle-card-parser.html
Part 5: http://hackcorrelation.blogspot.de/2013/07/txtr-beagle-native-code-analysis.html
Nevertheless, quite a few people have expressed their problems in being able to work out what compression has been used and the window size so this will aid in future reverse engineering.
Once the file has been loaded, depending on the IDA version used, you might not see the offending function listed in the functions window. A simple search takes care of that:

Scrolling through the function you will see several references to other functions, here is an example below:
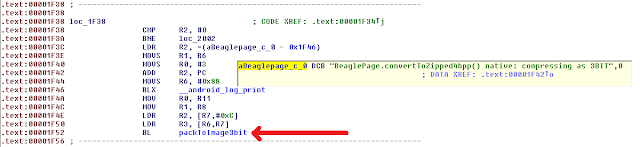
IDA allows you to even see the nice logging output.
Further down below is the call to the "mysterious" compress2K method:
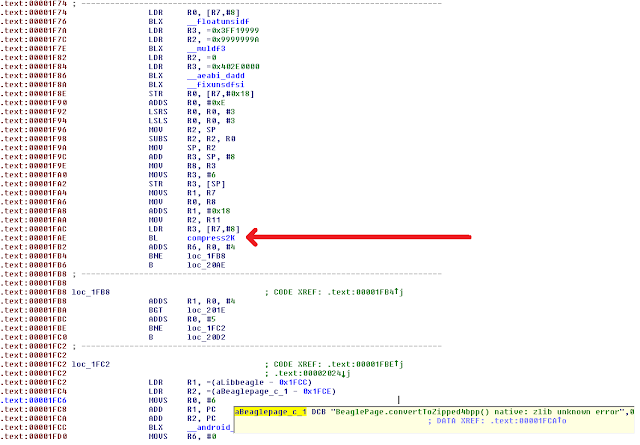
As noted, the log message give a possible suggestion to the compression method being used.
We'll start looking at individual functions, starting with the compression one:

It looks like it just initializes the deflate library and iterates on the data to be compressed.
I will not go into the details of figuring out what the parameters do, it is not needed for this analysis.
The deflate method looks like a standard function call:
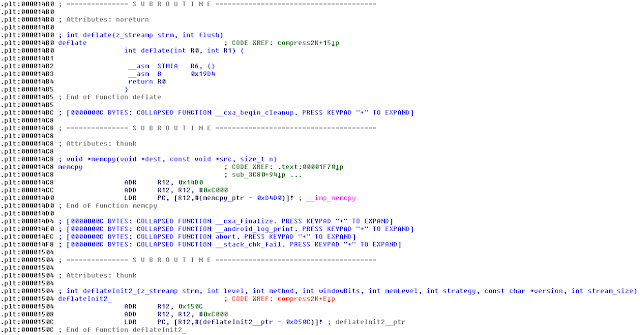
The deflateInit function declaration nicely lists all the available parameters and the caller method.
The packToDitheredImage3bit function cannot be decompiled by the armludda plugin but the packToImage3bit can, giving some insight as to how the image buffer is pre-processed.
Going with just the name we can figure out exactly what the function does, but this is only an exercise.
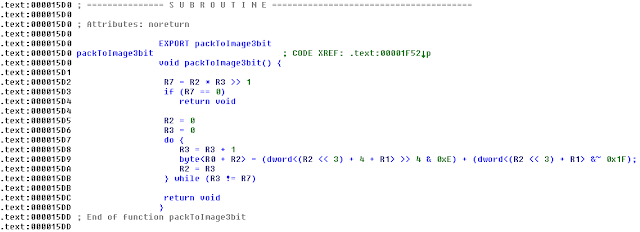
As you can see it's just taking the lower portion of the two integers send by the Java program and packing them into a single byte, since each integer has only the lower 4 bits used.
Still the question remains why the developers went with the native call approach. I'm guessing speed but I'm not really sure if a carefully crafted Java program cannot achieve better performance. As any Java developer knows native calls really take a toll on speed and should be called as seldom as possible.
In this case, if native was really needed, a better approach would be to have the processing all done at once or through the least calls needed. Perhaps every 10 pages or so.
While transferring books both my CPU cores are maxed out which means that perhaps the limiting factor in transfer speed is really the CPU and not the Bluetooth transfer rate. Someone needs to do an analysis on this.
Any information above can be gathered as well by building a dummy Android app and doing calls the native .so library.
Anyway, considering that the goal was to make the reader open to 3rd party content this is already going too far. I've seen that already a Calibre plugin is in the works, I'll post the link here as soon as it's readily available.
First, I'm using the IDA disassembler which is pretty expensive and thus quite extensively pirated. Unfortunately there are no freely available tools that I know of that can perform this task.
Second, I really suck at assembler and C so might not be the best person to do these analysis. I've used the freely available Thumb decompiler plugin which is able to translate assembly into readable code but only in about 30% of the cases. There's no substitute for knowledge, it seems.
Part 1: http://hackcorrelation.blogspot.de/2013/07/txtr-beagle-teardown-part-1.html
Part 2: http://hackcorrelation.blogspot.de/2013/07/txtr-beagle-part-two-software.html
Part 3: http://hackcorrelation.blogspot.de/2013/07/txtr-beagle-part-3-storage-and-transfer.html
Part 4: http://hackcorellation.blogspot.de/2013/07/txtr-beagle-card-parser.html
Nevertheless, quite a few people have expressed their problems in being able to work out what compression has been used and the window size so this will aid in future reverse engineering.
Once the file has been loaded, depending on the IDA version used, you might not see the offending function listed in the functions window. A simple search takes care of that:

Scrolling through the function you will see several references to other functions, here is an example below:

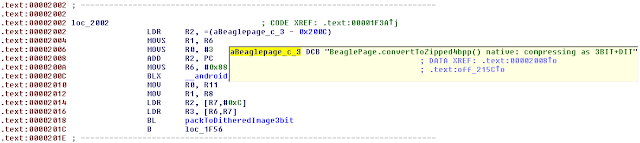
The branching is based on some conditions, presumably the 4th parameter of call:
this.mCompressedBytes = convertToZipped4bpp(arrayOfInt, 600, 800, i, bool3);
Where in almost all cases i==16. What we are interested in is the call below but you'll see why I pasted the "packToImage3bit" call:

IDA allows you to even see the nice logging output.
Further down below is the call to the "mysterious" compress2K method:

As noted, the log message give a possible suggestion to the compression method being used.
We'll start looking at individual functions, starting with the compression one:

It looks like it just initializes the deflate library and iterates on the data to be compressed.
I will not go into the details of figuring out what the parameters do, it is not needed for this analysis.
The deflate method looks like a standard function call:

The deflateInit function declaration nicely lists all the available parameters and the caller method.
The packToDitheredImage3bit function cannot be decompiled by the armludda plugin but the packToImage3bit can, giving some insight as to how the image buffer is pre-processed.
Going with just the name we can figure out exactly what the function does, but this is only an exercise.

As you can see it's just taking the lower portion of the two integers send by the Java program and packing them into a single byte, since each integer has only the lower 4 bits used.
Conclusion
There's not much to say except to say that no program is really safe from any reverse-engineering techniques. I consider myself a complete beginner when it comes to this and I was able to gather all the information above in less than an hour, almost on par with the time it took me to do this write-up.
Still the question remains why the developers went with the native call approach. I'm guessing speed but I'm not really sure if a carefully crafted Java program cannot achieve better performance. As any Java developer knows native calls really take a toll on speed and should be called as seldom as possible.
In this case, if native was really needed, a better approach would be to have the processing all done at once or through the least calls needed. Perhaps every 10 pages or so.
While transferring books both my CPU cores are maxed out which means that perhaps the limiting factor in transfer speed is really the CPU and not the Bluetooth transfer rate. Someone needs to do an analysis on this.
Any information above can be gathered as well by building a dummy Android app and doing calls the native .so library.
Anyway, considering that the goal was to make the reader open to 3rd party content this is already going too far. I've seen that already a Calibre plugin is in the works, I'll post the link here as soon as it's readily available.
Comments
Post a Comment
Due to spammers, comments sometimes will go into a moderation queue. Apologies to real users.